Kopule/funkcje łączące
Angielskie słowo copula, używane w kontekście generowania wielowymiarowych zmiennych zależnych, najczęściej tłumaczone jest niepoprawnie na polskie słowo kopuła. Odpowiedniejszym tłumaczeniem jest polskie słowo pochodzenia łacińskiego kopula oznaczające łącznik w znaczeniu formy czasownika być łączącej podmiot i orzeczenie. Możemy też używać określenia funkcja łącząca. Warto dodać, że wikipedia dopuszcza nawet pisownię copula traktując to słowo jako już polskie, słownik PWN jest bardziej konserwatywny.
Powyżej opisaliśmy jak generować zależne zmienne losowe o łącznym rozkładzie normalnym. W wielu zastosowaniach przydatna jest możliwość generowania zmiennych o zadanej strukturze zależności i o dowolnych rozkładach brzegowych. Do tego celu można wykorzystać kopule, czyli funkcje łączące. Za tym narzędziem stoi bardzo ciekawa teoria, jak również wiele zastosowań, szczególnie w finansach i ubezpieczeniach. Poniżej przedstawimy kilka przykładów użycia kopuli do generowania zależnych zmiennych.
Kopula to wielowymiarowy rozkład określony na kostce , taki, że rozkłady brzegowe dla każdej współrzędnej są jednostajne na odcinku . Poniżej przez będziemy oznaczać dystrybuantę tego rozkładu. Poniższe twierdzenie wyjaśnia dlaczego kopule są ciekawe.
Twierdzenie Sklara
Dla zadanego rozkładu określonego na wymiarowej przestrzeni i odpowiadających mu rozkładów brzegowych istnieje kopula , taka że . Oznacza to, że każdy rodzaj zależności można opisać pewną kopulą.
Rozważmy przypadek dwuwymiarowy. Dla zmiennej dwuwymiarowej o rozkładzie o brzegowych rozkładach istnieje kopula taka, że Co więcej, jeżeli brzegowe dystrybuanty są ciągłe, to jest wyznaczona jednoznacznie.
Jeżeli chcemy generować obserwacje z rozkładu , to wystarczy, że potrafimy generować obserwacje z kopuli i znamy rozkłady , . Wszystkich możliwych kopuli jest nieskończenie wiele, ale w zastosowaniach najczęściej pojawiają się następujące klasy kopul.
Kopula Gaussowska. W przypadku dwuwymiarowym kopuła Gaussowska wyrażona jest następującym wzorem gdzie jest parametrem. Ta kopula odpowiada zależności pomiędzy zmiennymi o łącznym rozkładzie normalnym z korelacją . Podobnie definiuje się kopule Gausowskie dla wyższych wymiarów.
Kopula Archimedesowska. Dla wymiarów kopuła Archimedesowska wyraża się wzorem gdzie to tzw. funkcja generująca, spełniająca warunki:
- (1) ,
- (2) ,
- (3) ,
- (4) .
Wybierając odpowiednie funkcje generujące, otrzymujemy następujące podklasy kopuli.
- Kopula produktowa, w tym przypadku funkcja generująca zadana jest wzorem
- Kopula Claytona, w tym przypadku funkcja generująca zadana jest wzorem
- Kopula Gumbela, w tym przypadku funkcja generująca zadana jest wzorem
- Kopula Franka, w tym przypadku funkcja generująca zadana jest wzorem
W pakiecie copula do operacji na kopulach służą funkcje:
dCopula(copula,u), wylicza gęstość kopulicopulaw punkcieu,pCopula(copula,u), wylicza dystrybuantę kopuli w punkcieu,rCopula(copula,n), generujenwartości z kopulicopula.
Pierwszym argumentem tych funkcji jest obiekt klasy copula, opisujący wielowymiarowy rozkład na kostce jednostkowej. Taki obiekt możemy zainicjować używając jednej z funkcji wymienionych w kolejnej tabeli. Gęstości i przykładowe próby wylosowane z wybranych kopuli przedstawione są na kolejnym rysunku.
Zobaczmy jak w programie R zainicjować obiekt typu copula i wygenerować wektor zmiennych o zadanej strukturze zależności.
set.seed(1313)
library(copula)
(norm.cop <- normalCopula(0.5))
## Normal copula family
## Dimension: 2
## Parameters:
## rho.1 = 0.5
Wewnątrz obiektu przechowywane są informacje o strukturze.
str(norm.cop)
## Formal class 'normalCopula' [package "copula"] with 8 slots
## ..@ dispstr : chr "ex"
## ..@ getRho :function (obj)
## ..@ dimension : int 2
## ..@ parameters : num 0.5
## ..@ param.names : chr "rho.1"
## ..@ param.lowbnd: num -1
## ..@ param.upbnd : num 1
## ..@ fullname : chr "Normal copula family"
Używając funkcji rcopula generujemy 1000 obserwacji.
x <- rCopula(1000, norm.cop)
head(x)
## [,1] [,2]
## [1,] 0.9017415 0.7996649
## [2,] 0.5633166 0.2781131
## [3,] 0.5018875 0.3524915
## [4,] 0.4723126 0.6805997
## [5,] 0.9818537 0.9222935
## [6,] 0.4294685 0.7537388
Na poniższym przykładzie wygenerujemy 40 obserwacji z rozkładu, którego rozkładami brzegowymi są rozkłady wykładnicze o parametrze , a struktura zależności opisana jest kopulą Claytona.
Poniżej najpierw tworzymy obiekt z definicją kopuli Claytona, następnie generujemy 40 obserwacji z zadanej kopuli. Nakładamy na wygenerowane obserwacje odwrotne dystrybuanty, by otrzymać zmienne o żadnych rozkładach brzegowych, poniżej nałożono odwrotną dla rozkładu wykładniczego z rate=2.
N <- 40
clayton.cop <- claytonCopula(1, dim = 2)
x <- rCopula(N, clayton.cop)
y <- cbind(qexp(x[,1], rate=2), qexp(x[,2], rate=2))
head(y)
## [,1] [,2]
## [1,] 0.1370687 0.2053138
## [2,] 0.4471693 0.2810865
## [3,] 0.4311381 1.8271957
## [4,] 0.5594571 0.9528302
## [5,] 0.2340921 0.4423038
## [6,] 0.2403673 0.4180288
Kopule stosowane są w wielu zagadnieniach. Poniżej przedstawimy przykład badania mocy dwóch testów korelacji, gdy dwuwymiarowa zmienna ma brzegowe rozkłady wykładnicze i zależność opisaną przez kopulę Claytona.
Porównajmy test dla współczynnika korelacji Pearsona i Spearmana. Pierwszy zakłada normalny rozkład obserwacji, zobaczymy jak niespełnienie tego założenia wpływa na moc.
Moc testu ocenimy na podstawie 1000 powtórzeń, testy pracują na poziomie istotności 0.05.
N <- 40
pv <- matrix(0, 2, 1000)
clayton.cop <- claytonCopula(1, dim = 2)
rownames(pv) <- c("Pearson", "Spearman")
Losujemy dwa wektory o zadanej strukturze zależności. Następnie dwoma testami wyznaczamy p-wartość dla hipotezy zerowej o braku korelacji.
for (i in 1:1000) {
x <- rCopula(N, clayton.cop)
y <- cbind(qexp(x[,1],2), qexp(x[,2],2))
pv[1, i] <- cor.test(y[,1], y[,2], method="pearson")$p.value
pv[2, i] <- cor.test(y[,1], y[,2], method="spearman")$p.value
}
Liczymy moc, czyli jak często p-wartość jest poniżej ustalonego progu. Tutaj 0.05. Gdy spojrzymy na wyniki, zauważymy, że test Spearmana ma tutaj prawie dwukrotnie wyższą moc!
rowMeans(pv < 0.05)
## Pearson Spearman
## 0.473 0.855
W zagadnieniach praktycznych, często nie wiemy z jakiej rodziny wybrać rozkłady brzegowe. W takich sytuacjach dobrym pomysłem jest użycie empirycznej dystrybuanty. Funkcję odwrotną do dystrybuanty empirycznej (która nie jest monotoniczna, ale to tzw. szczegół techniczny) jest funkcja quantile().
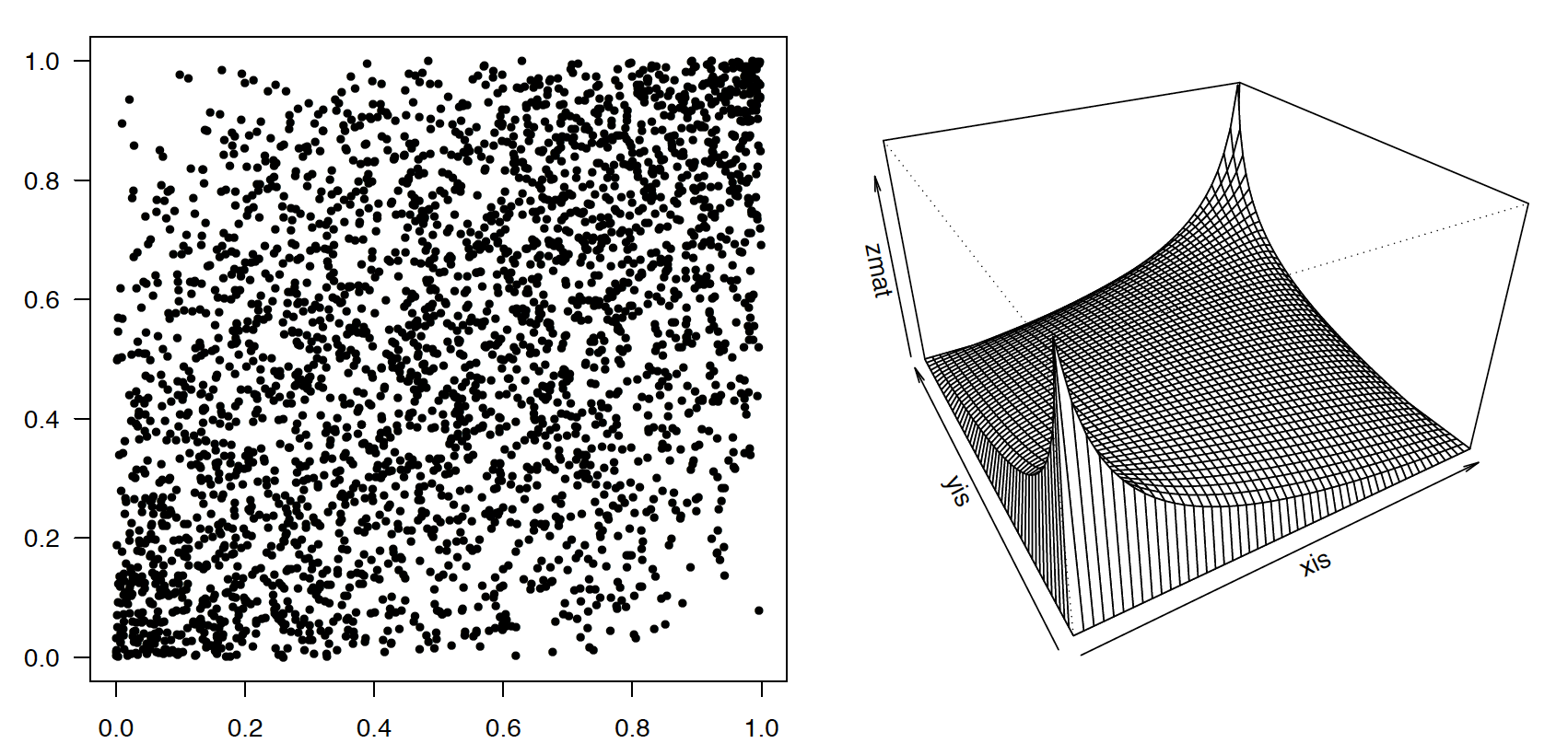
Kopula Gaussowska rho=0.5. Przykładowa 200 elementowa próba przedstawiona jest po lewej stronie, po prawej stronie przedstawiana jest gęstość
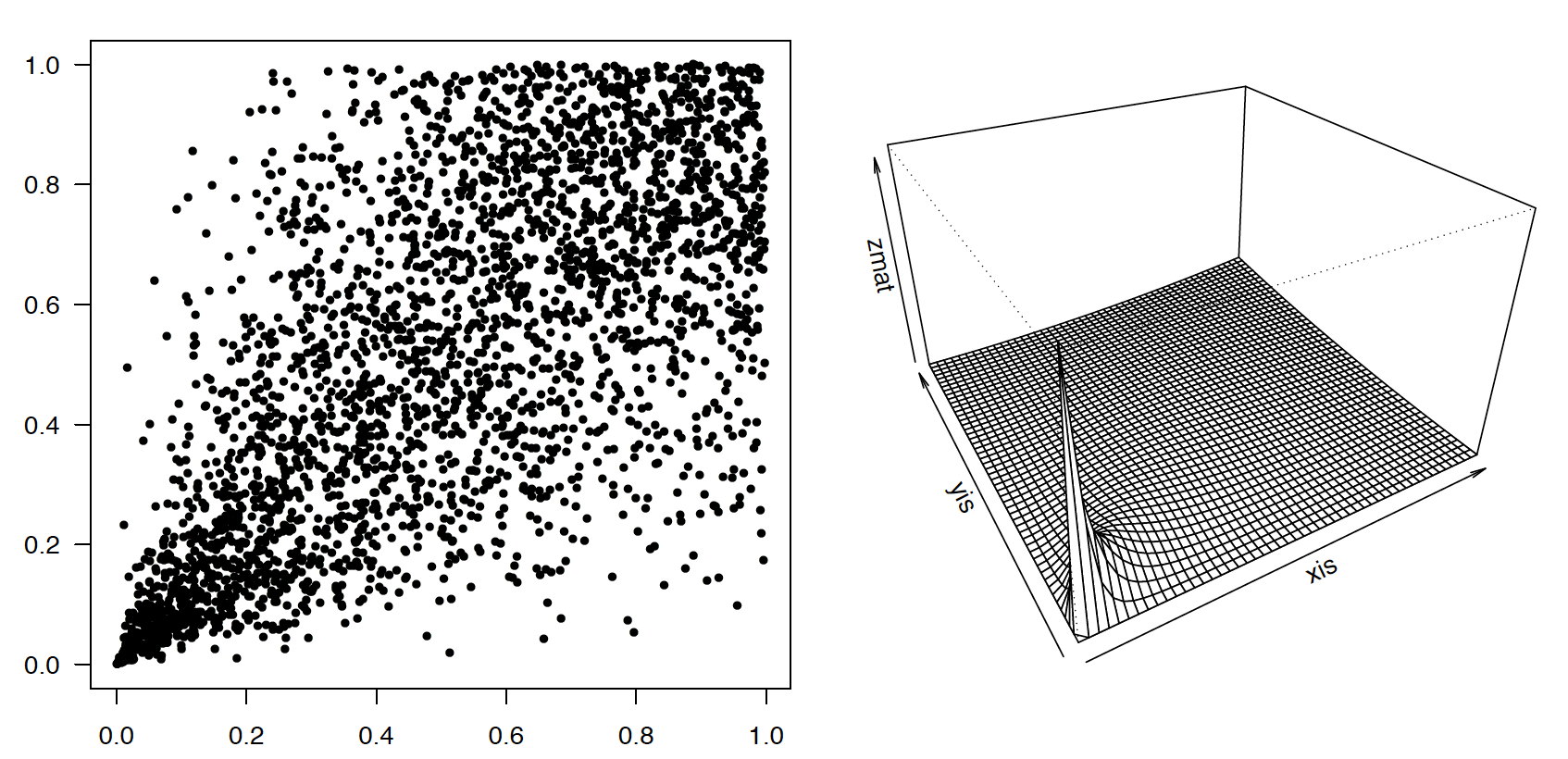
Kopula Claytona z parametrem 2
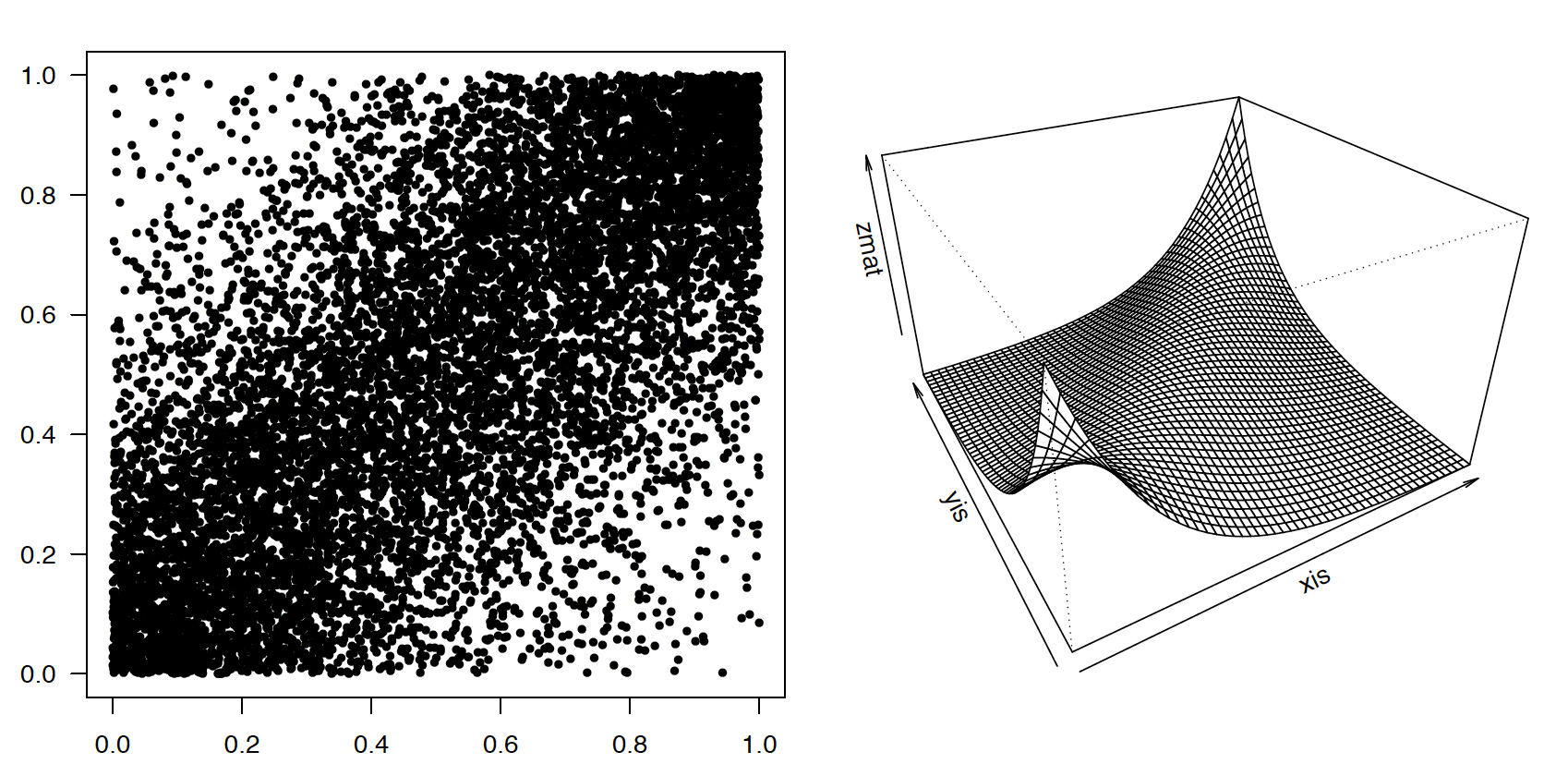
Kopula Franka z parametrem 5
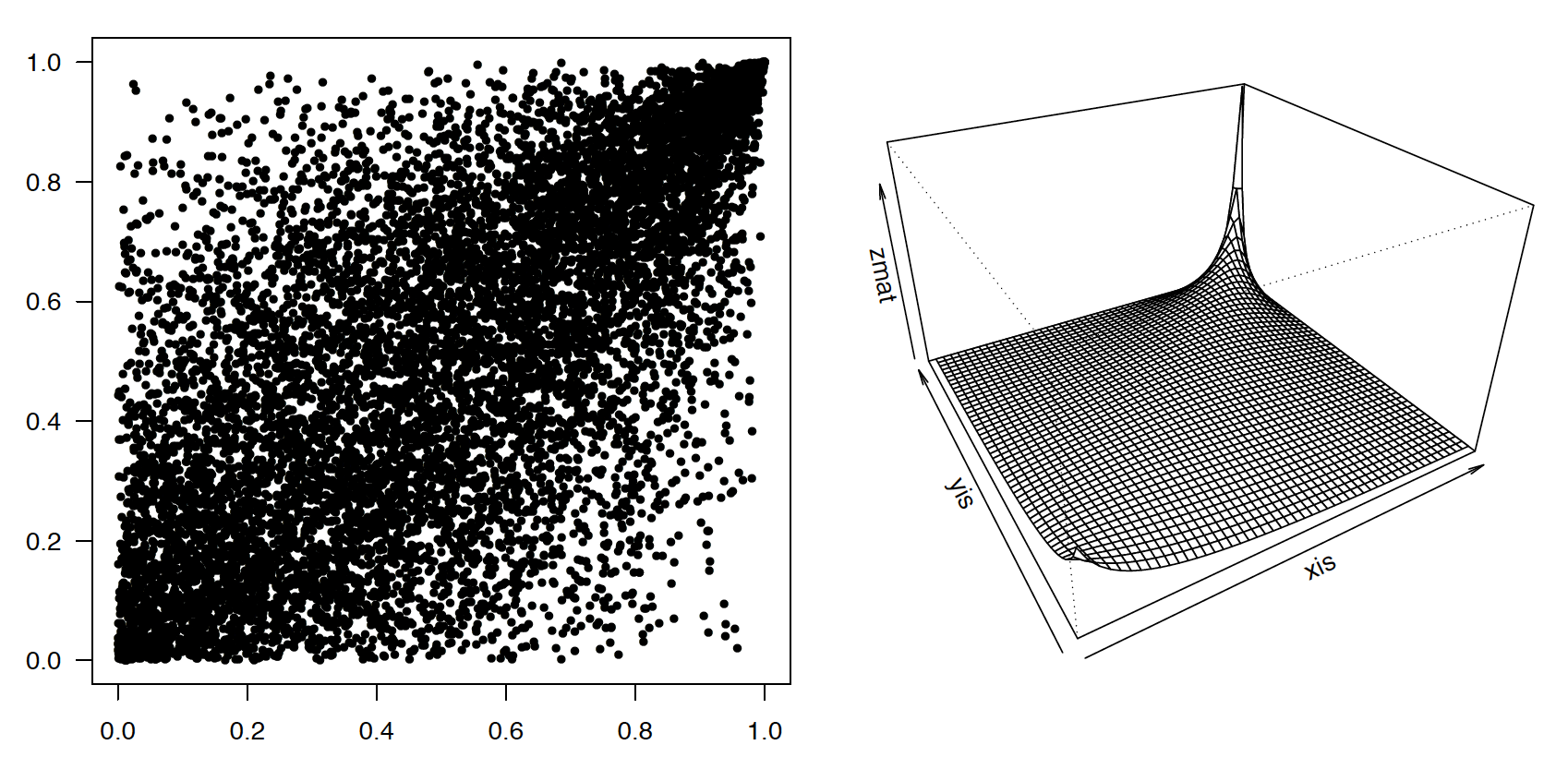
Kopula Gumbela z parametrem 2. Struktura zależności jest niesymetryczna ale inna niż w przypadku kopuli Claytona
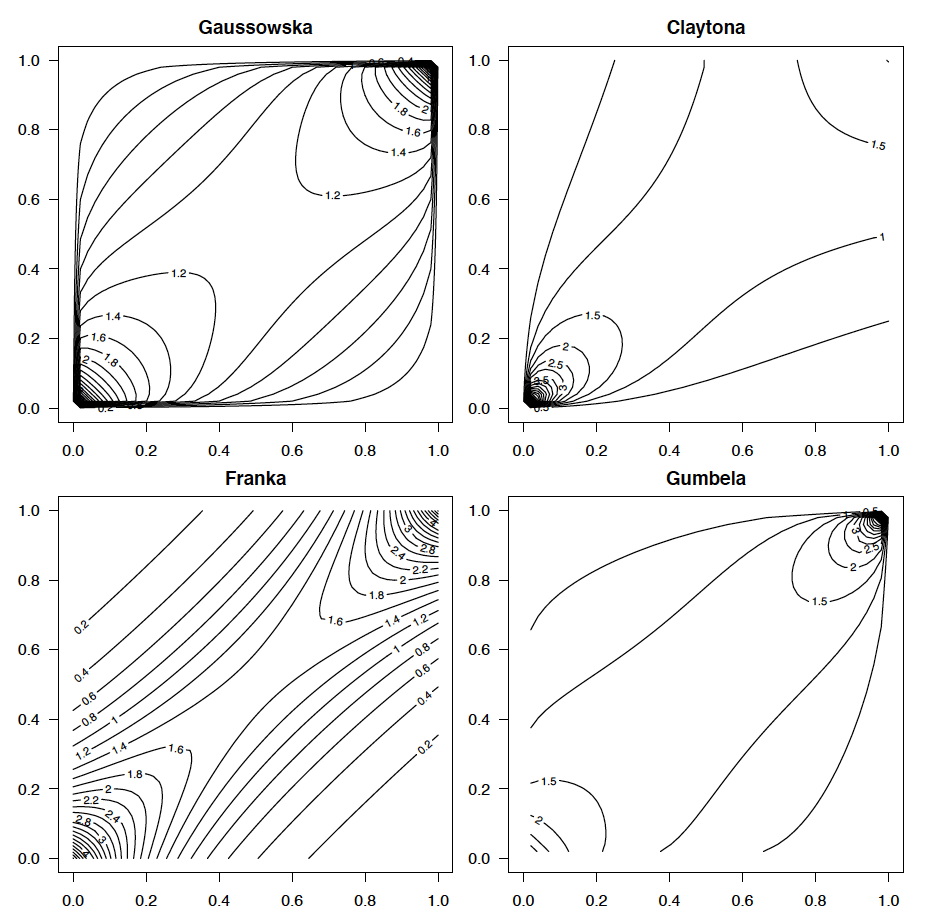
Wykresy konturowe dla gęstości różnych kopuli

Funkcje tworzące kopule poszczególnych klas