Jak badać zależności pomiędzy parą zmiennych?
Testów weryfikujących strukturę zależności pomiędzy parą zmiennych jest co niemiara. W języku polskim całkiem bogata kolekcja testów jest przedstawiona w książce Ryszarda Magiery ,,Modele i metody statystyki Matematycznej''.
Zamiast jednak opisywać wszystkie testy statystyczne (co jest niemożliwe) poniżej skupimy się na przedstawieniu tych najbardziej popularnych, tworzących swego rodzaju szkielet, który można rozbudowywać w różnych kierunkach.
Jak weryfikować niezależność dwóch zmiennych jakościowych?
Problem: Mamy dwie zmienne jakościowe (np. kolor oczu i kolor włosów), ciekawi jesteśmy czy jest pomiędzy nimi zależność.
Model: Przyjmijmy, że obserwujemy dwuwymiarową zmienną losową . przyjmuje wartości ze zbioru a przyjmuje wartości ze zbioru .
Brzegowy rozkład zmiennej X określmy jako a zmiennej jako . Łączny rozkład zmiennych określimy jako .
Hipoteza: Określmy hipotezę zerową (niezależności), dla każdego
Hipoteza alternatywna jest taka, że dla dowolnego ta równość nie zachodzi.
Statystyka testowa:
Statystyka testowa jest oparta o tablicę kontyngencji (tablicę zliczeń).
| Y \ X | ||||
|---|---|---|---|---|
| ... | ||||
| ... | ... | ... | ||
| ... |
Tablica kontyngencji opisuje obserwowane w danych liczebności wystąpienia poszczególnych kombinacji wartości. Statystyka testowa porównuje te wartości z wartościami oczekiwanymi, przy założeniu prawdziwej hipotezy zerowej.
Ogólna postać statystyki testowej w teście to
gdzie oznacza obserwowane liczebności, oczekiwane liczebności dla i-tej komórki.
Ta generyczna postać statystyki testowej, w tym konkretnym przypadku przyjmuje postać (indeksy z kropkami to sumy po wierszach/kolumnach)
Ta statystyka testowa ma asymptotyczny rozkład .
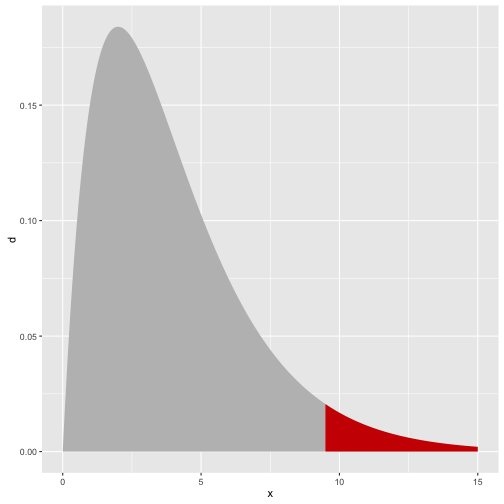
Za obszar odrzucenia przyjmuje się przedział postaci . Przykładowa gęstość rozkładu z zaznaczonym kwartylem rzędu .
library(ggplot2)
x <- seq(0,15,0.01)
(q <- qchisq(0.95, 4))
## [1] 9.487729
df <- data.frame(x, d = dchisq(x,4), rejection = x>q )
ggplot(df, aes(x, y=d, fill=rejection)) + geom_area() + theme(legend.position="none") + scale_fill_manual(values=c("grey","red3"))
Przykład
Rozważmy następującą tabelę liczebności. Opisuje ona występowanie różnych kolorów oczu / włosów.
(tab <- HairEyeColor[,,1])
## Eye
## Hair Brown Blue Hazel Green
## Black 32 11 10 3
## Brown 53 50 25 15
## Red 10 10 7 7
## Blond 3 30 5 8
# archivist::aread("pbiecek/Przewodnik/arepo/a3666b4084daa5db9251dc36e3286298")
Aby przeprowadzić test można wykorzystać funkcję chisq.test(). Wyznacza ona zarówno macierz oczekiwanych częstości, statystykę testową jak i wartość p.
wynik <- chisq.test(tab)
wynik$p.value
## [1] 4.447279e-06
wynik$statistic
## X-squared
## 41.28029
wynik$expected
## Eye
## Hair Brown Blue Hazel Green
## Black 19.67025 20.27240 9.433692 6.623656
## Brown 50.22939 51.76703 24.089606 16.913978
## Red 11.94265 12.30824 5.727599 4.021505
## Blond 16.15771 16.65233 7.749104 5.440860
wynik$observed
## Eye
## Hair Brown Blue Hazel Green
## Black 32 11 10 3
## Brown 53 50 25 15
## Red 10 10 7 7
## Blond 3 30 5 8
Jak weryfikować niezależność dwóch zmiennych binarnych?
Specyficzną wersją testu na niezależność dwóch zmiennych jakościowych jest test dla dwóch zmiennych binarnych. Zamiast wykorzystywać w tym przypadku asymptotyczny rozkład statystyki testowej można badać dokładny rozkład statystyki testowej. Stąd też nazwa testu - dokładny test Fishera.
Statystyka testowa jest oparta o tablicę kontyngencji
| Y \ X | ||
|---|---|---|
o rozkładzie hipergeometrycznym.
Jeżeli badamy zależnośc pomiędzy parą zmiennych binarnych to zalecane jest użycie tego testu. Umożliwia on również weryfikowanie hipotez kierunkowych (a więc częstsze/rzadsze niż przypadkowe współwystępowanie ).
Przykład
Ograniczmy nadanie kolorów oczu do niebieskie/brązowe a włosów do czarne / blond.
tab22 <- tab[c(1,4),c(1,2)]
fisher.test(tab22)
##
## Fisher's Exact Test for Count Data
##
## data: tab22
## p-value = 7.391e-09
## alternative hypothesis: true odds ratio is not equal to 1
## 95 percent confidence interval:
## 6.673302 168.168624
## sample estimates:
## odds ratio
## 27.39659
Jak weryfikować niezależność dwóch zmiennych ilościowych?
Dla zmiennych ilościowych zależność może przybierać bardzo różną postać. Możemy obserwować zależność w kwadratach (czyli korelacje wartości skranych bez względu na ich znak), uwikłanie zmiennych, wiele możliwych odstępst od niezależności.
Z powodu łatwości interpretacji, najczęściej w pierwszym kroku interesują nas dwa rodzaje zależności: liniowa oraz monotoniczna. Do ich badania najczęściej wykorzystuje się testy na współczynnik korelacji Pearsona i Spearmana.
Dwuwymiarowy rozkład normalny
Model: Przyjmijmy, że obserwujemy dwuwymiarową zmienną losową z dwuwymiarowego rozkładu normalnego . Gdzie to macierz kowariancji, element poza przekątną oznaczny przez .
Hipoteza:
Statystyka testowa:
Statystyka testowa oparta jest o współczynnik korelacji Pearsona
Rozkład statystyki jest określony na odcinku [-1,1]. Aby ułatwić jej analizę stosowane jest następujące przekształcenie
Po takim przekształceniu statystyka ma rozkład i w oparciu o niego konstruowany jest obszar krytyczny. Dla dwustronnej hipotezy alternatywnej jest to obszar .
x <- seq(-5,5, .01)
(q <- qt(0.975, 5))
## [1] 2.570582
df <- data.frame(x, d = dt(x,5), rejection = abs(x)>q )
ggplot(df, aes(x, y=d, fill=rejection)) + geom_bar(stat="identity") + theme(legend.position="none") + scale_fill_manual(values=c("grey","red3"))
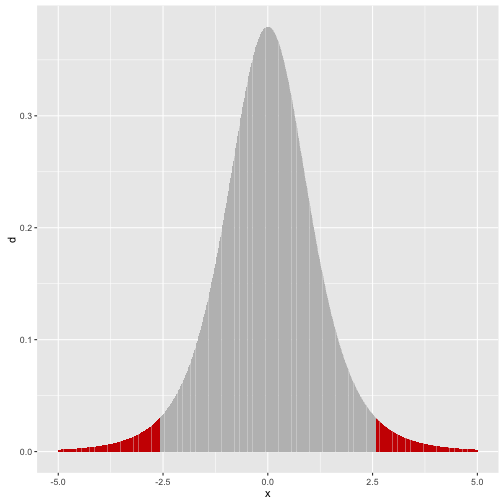
Czasem weryfikowana jest też inna hipoteza zerowa. Jeżeli chceny zbadać, czy korelacja jest istotnie różna (np. istotnie większa) od określonej wartości to interesuje nas raczej hipoteza.
Hipoteza:
Statystyka testowa:
W tym przypadku stosuje się inną transformację, tzw. transformację Fishera.
Przy prawdziwej hipotezie zerowej ta statystyka ma asymptotycznie rozkład normalny .
Znając rozkład możemy już w prosty sposób zbudować test statystyczny. Tę transformację można wykorzystać również do konstrukcji testu dla równości dwóch współczynników korelacji.
Korelacja rang
Założenie o dwuwymiarowym rozkładzie normalnym jest silnie ograniczające. Co prawda test Pearsona stosuje się nawet jeżeli zmienna nie ma rozkładu normalnego, ale jedynie do niego zbliżony. Wciąż jednak tego typu test wykrywa jedynie liniowe zależnosci.
Dlatego często stosowanym testem dla zbioru hipotez jest test korelacji Spearmana. Jest ona w stanie identyfikować zależności monotoniczne. Ideę testu Spearmana można streścić w określeniu: badanie korelacji rang.
Model: Przyjmijmy, że obserwujemy dwuwymiarową zmienną losową o rozkładzie ciągłym.
Oznaczmy dodatkowo , .
Hipoteza:
Statystyka testowa:
Statystyką testową jest korelacja Pearsona ale liczona dla rang, a nie oryginalnych obserwacji. Ponieważ średnia ranga to więc otrzymujemy
Po prostych przekształceniach otrzymujemy
Rozkład tej statystyki można tablicować dla małych . Asymptotycznie ma ona rozkład normalny z wariancją . Ale w implementacji najczęściej stosuje się podobną transformację co w przypadku testu Pearsona, czyli
Asymptotycznie ta statystyka ma rozkład .
A co jeżeli interesuje mnie inna zależność?
Opisane powyżej testy badają dwa rodzaje zależności - liniowy i monotoniczny.
Jeżeli interesuje nas inna klasa zależności to możliwy wybór jest albo przez badanie funkcji łączących (tzw. kopule) albo przez badanie zmiennych jakościowych. Każdą zmienną ilosciową możemy zdyskretyzować, dzieląc ją na pewną liczbę podprzedziałów i analizując zależność pomiedzy przedziałami (testem lub analizą korespondencji).
Przykład
Korzystając ze zbioru danych koty_ptaki sprawdzimy czy jest zależność pomiędzy długością kota a jego wagą.
library(PogromcyDanych)
head(koty_ptaki[,1:3])
## gatunek waga dlugosc
## 1 Tygrys 300 2.5
## 2 Lew 200 2.0
## 3 Jaguar 100 1.7
## 4 Puma 80 1.7
## 5 Leopard 70 1.4
## 6 Gepard 60 1.4
ggplot(koty_ptaki, aes(waga, dlugosc)) + geom_point(size=3) + geom_smooth(method="lm", color="grey", se=FALSE)
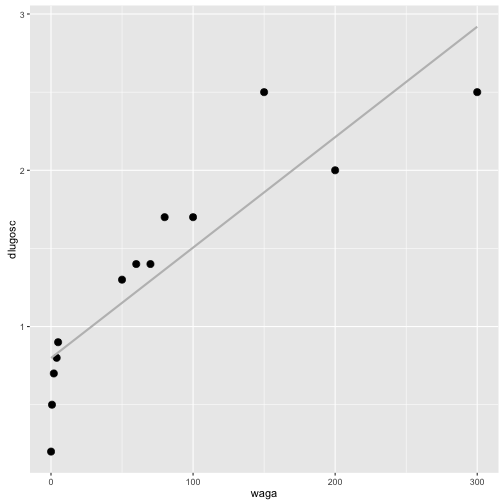
Korelację Pearsona (liniową) badalibyśmy testem cor.test()
cor.test(koty_ptaki$waga, koty_ptaki$dlugosc)
##
## Pearson's product-moment correlation
##
## data: koty_ptaki$waga and koty_ptaki$dlugosc
## t = 6.4499, df = 11, p-value = 4.743e-05
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## 0.6633850 0.9666441
## sample estimates:
## cor
## 0.8893128
Korelację Spearmana (monotoniczną) badalibyśmy testem cor.test(). Współczynnik korelacji rang jest prawie równy 1.
cor.test(koty_ptaki$waga, koty_ptaki$dlugosc, method="spearman")
## Warning in cor.test.default(koty_ptaki$waga, koty_ptaki$dlugosc, method =
## "spearman"): Cannot compute exact p-value with ties
##
## Spearman's rank correlation rho
##
## data: koty_ptaki$waga and koty_ptaki$dlugosc
## S = 4.5155, p-value = 3.401e-10
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.9875947
Po dyskretyzacji badalibyśmy np. następującą tabelę (widzimy silną zależność nawet bez testu).
table(cut(koty_ptaki$waga, c(0,20,110,400)),
cut(koty_ptaki$dlugosc, c(0, 1, 1.9, 3)))
##
## (0,1] (1,1.9] (1.9,3]
## (0,20] 5 0 0
## (20,110] 0 5 0
## (110,400] 0 0 3